Credit Predictor Bot Project
Credit Predictor Bot
The Problem
For this project I really wanted to embrace the spirit of Fintech, so I decided to add a spin to a popular Kaggle dataset. My idea is that I can pitch our credit consulting bot to major credit card providers. My bot allows customers to find out how likely they are to default on their payment using various machine learning methods, it even gives them a percentage! Potential customers interact with an Amazon Lex bot that is powered by An Amazon Lambda function.
I believe that this type of analysis is extremely valuable to financial institutions as it allows the business to accuraately detect potential default which impacts the bottom line; The bot also gives the customers of the business a tool to correct reckless credit behavior prior to defaulting on their loan.
Approach to the Solution
I decided to test several methods of machine learning prior to deploying our Lex Bot. We used the Logistic Regression, Naive Random Oversampling, SMOTE, SMOTEEN, and Clustered Centroid machine learning methods to solve this problem. To determine the best model we looked at accuracy score and the imbalanced classification reports. I also used deep learning to cover all bases.
Initial Results
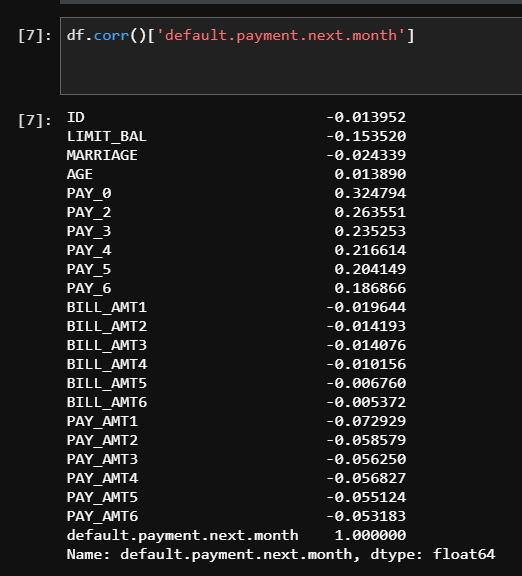
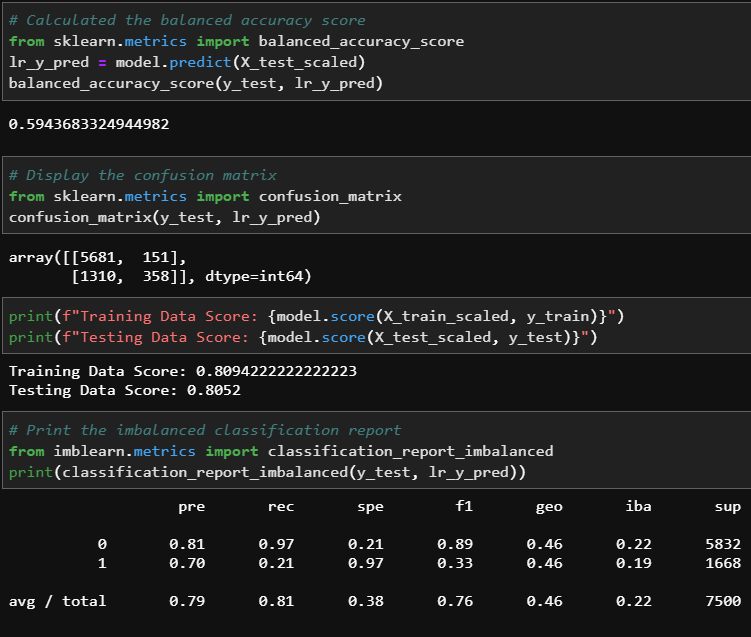
As you will see below, my initial results weren’t very good. After I downloaded the dataset from Kaggle, we inspected the data-set by using the .corr method in Python to see which columns were most correlated to our target. I then created the X and y training variables. Our initial results were very low. When I used the data in the Simple Logistic Regression model, the results (seen below) were not favorable. Our initial Balanced Accuracy Score was 59%; I also saw that the Recall Score was at 21% for predicting default (1s) and our F1 score was at 33%. Based on these results, I knew that I needed to make changes immediately.
Feature Engineering

While the data-set provided us with 30,000 rows of data, one of the limitations is that it doesn’t provide much context. Ideally, I’d like to see columns include information such as, “Income,” “Debt to Income Ratio,” “Previous Default” etc. Since I didn’t have the data I felt like I needed, my challenge was to create new features using the data that was provided. This made our project challenging yet rewarding.
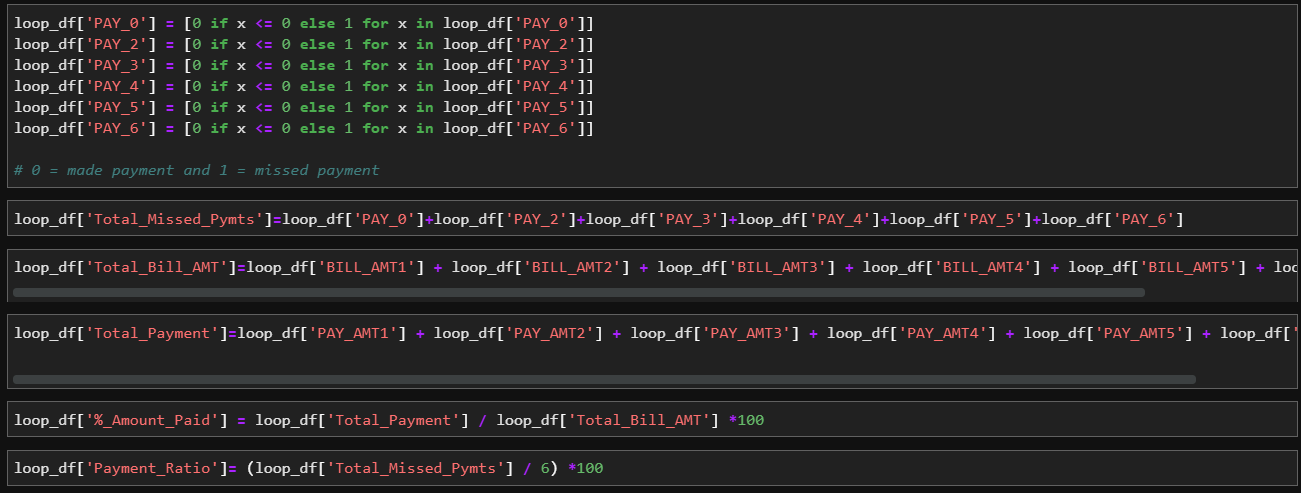
The most correlated columns were the PAY0-PAY6 columns. These features represented if the customer made or missed payments within the last 6 months. I decided that I should make a feature that represents the total amount of payments that the customer missed in the last six months. From there I created a feature that measures the percentage of payments that the customer has missed (Ex: 2 payments missed is 2/6 or 33.33%).
Finally, I created features that measure the customer’s total bill for 6 months as well as the total payment amount for the same time period.
Creating the new features
Showing the new correlation
New scores
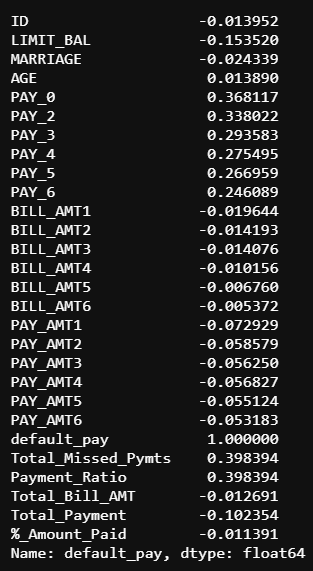
When I ran the .corr function after added the features, I discovered that I had created features that were more correlated to our taget than the pre-existing features. I also saw that every score increased, therefore, based on the new results I felt comfortable moving forward with our testing. Below you will see every method that I used to predict credit card default. You will see the creation of the pickle file(these are used to load the data into Lambda), accuracy score, balanced accuracy report and an example of the bot that I made in Lex for each method.
Logistic Regression Model

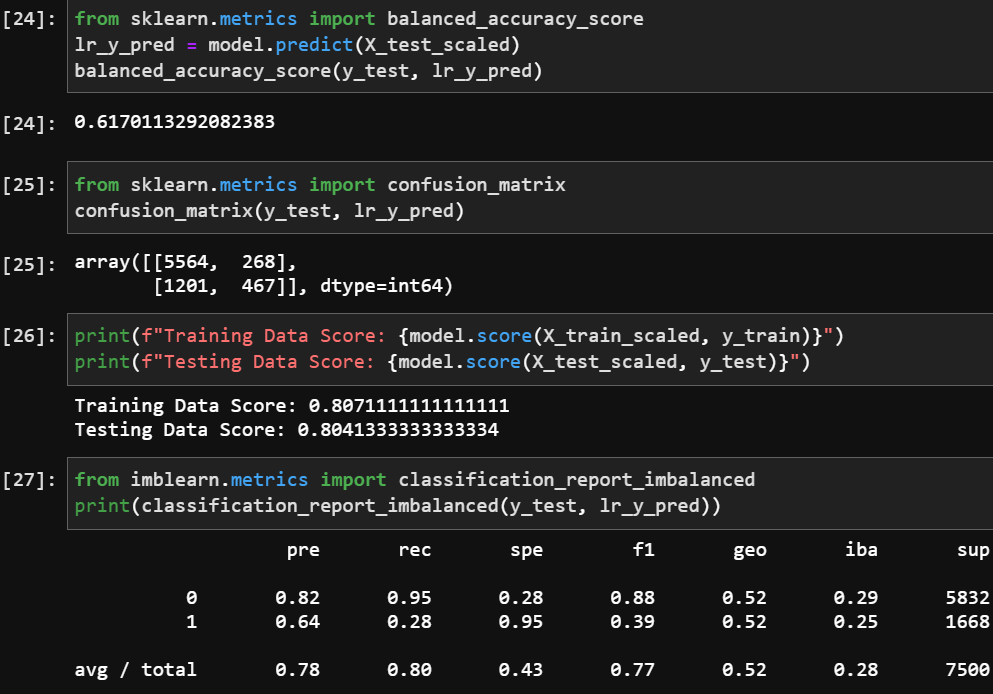
Below are the scores for the Logistic Regression model. You will notice that the balanced accuracy score is 3% better than the initial results. It is also clear that the prediction of default (1) increased by 4%.
Logistic regression scores
Naive Random Oversampling
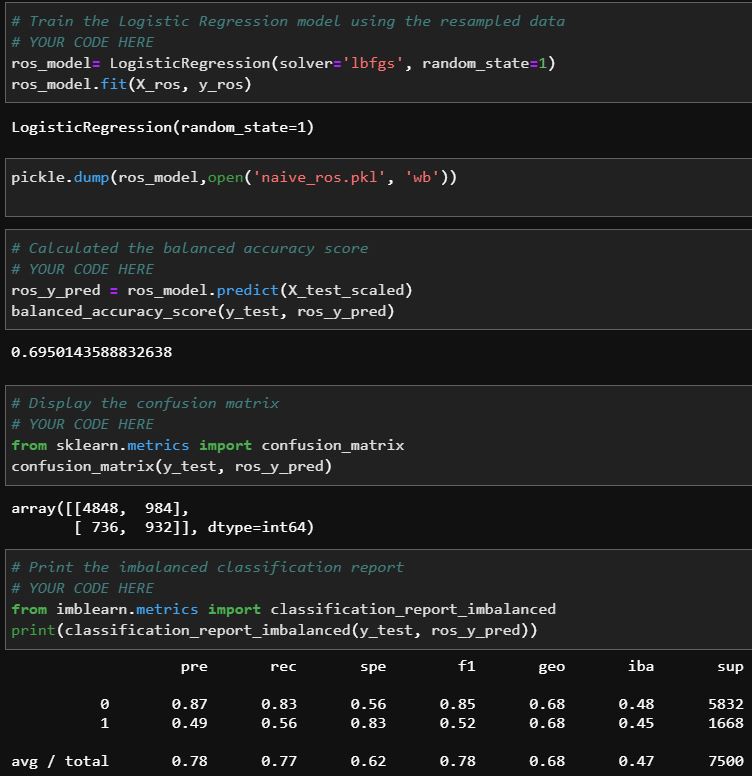
Below are the Naive Random Oversampling results. You will see that while the balanced accuracy score increased by 8% over our initial results, the prediction and recall scores were significantly lower than the previous model. I continued to look for the perfect machine learning match.
NAIVE Random Oversampling scores
Clustered Centroid
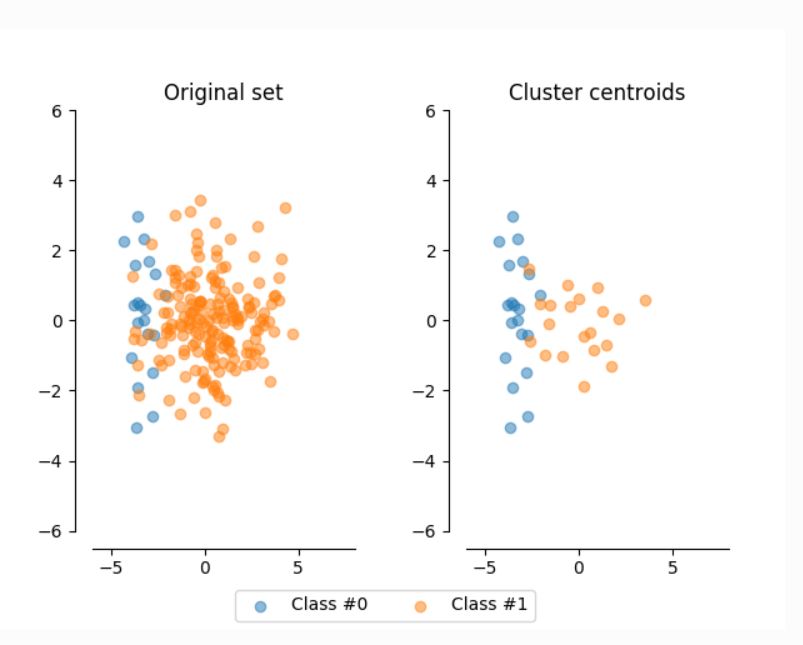
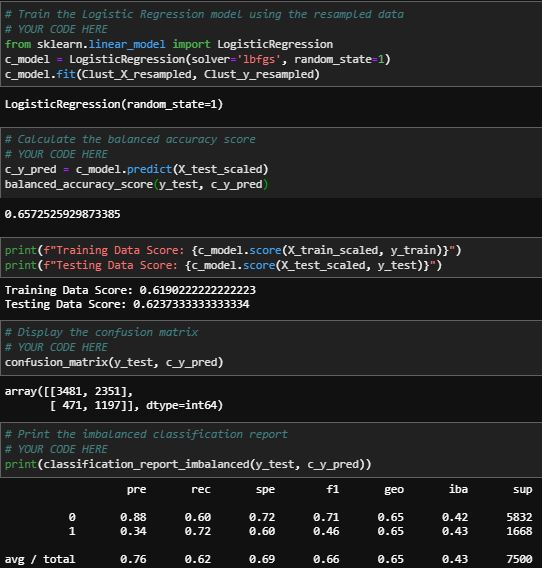
Below are the Clustered Centroid results. This method barely outperformed the original test in regards to the balanced accuracy score. It performed worse in every other measurable category. I decided against using this method.
Clustered Centroid scores
SMOTE
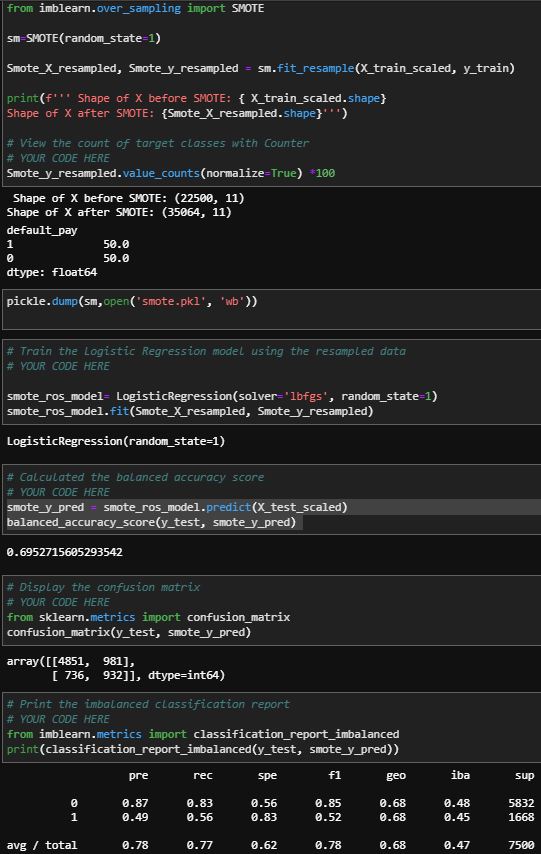
These are the Smote results. The balanced accuracy score is 10% higher than the original results, however, the ability to predict default is ability to predict default is only 49%; This metric is actually worse than the original data.
SMOTE scores
SMOTEENN
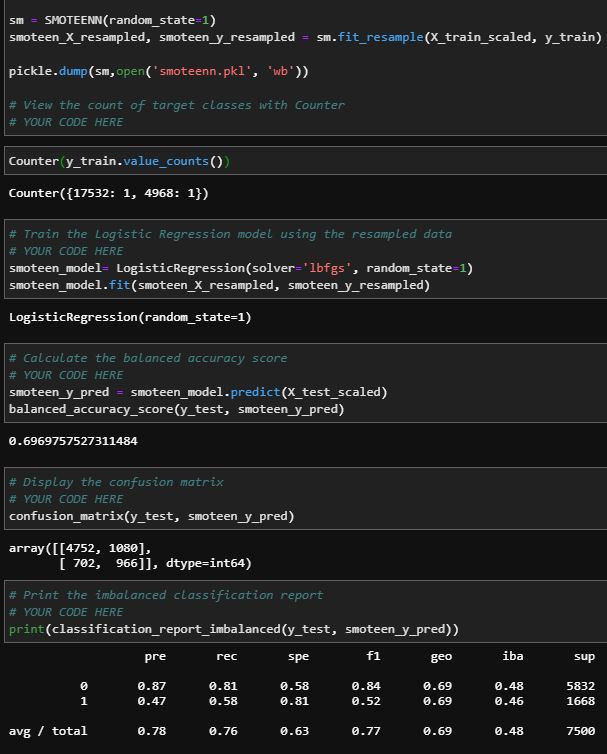
The Smoteenn results were very similar to the Smote example. This method has the best balanced accuracy score, however it was one of the worst at predicting default.
SMOTEEN scores
Deep Learning
Because the standard machine learning methods rendered results that were inconsistent, I turned our attention to deep learning. I created one single layer model and one multi-layered model and tested them against each other to see which one returned the most favorable results.
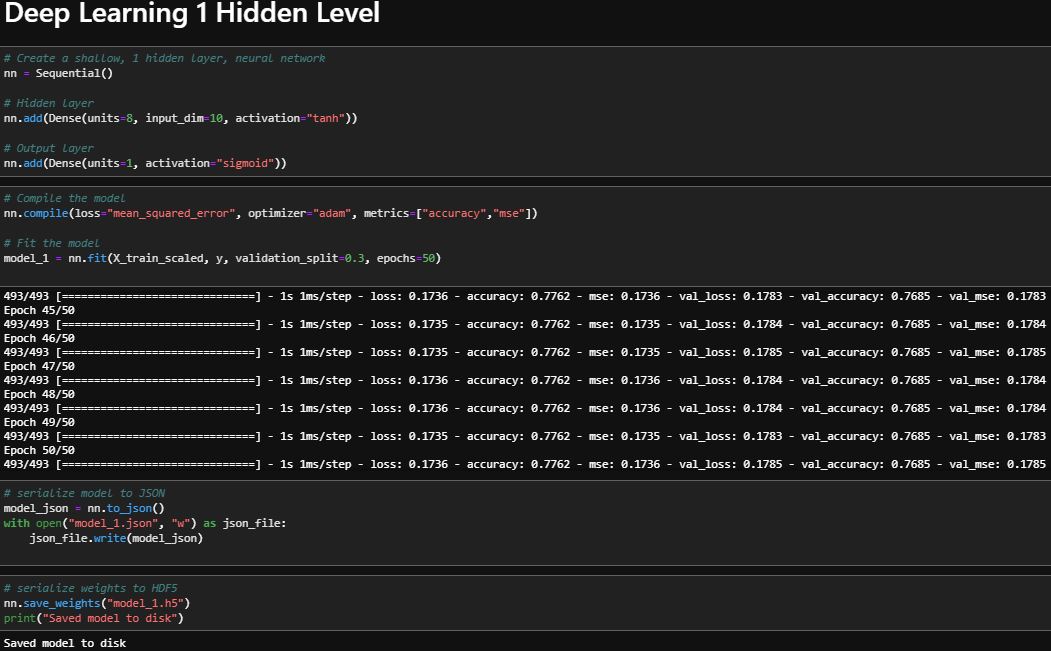
Single layer DEEP LEARNING

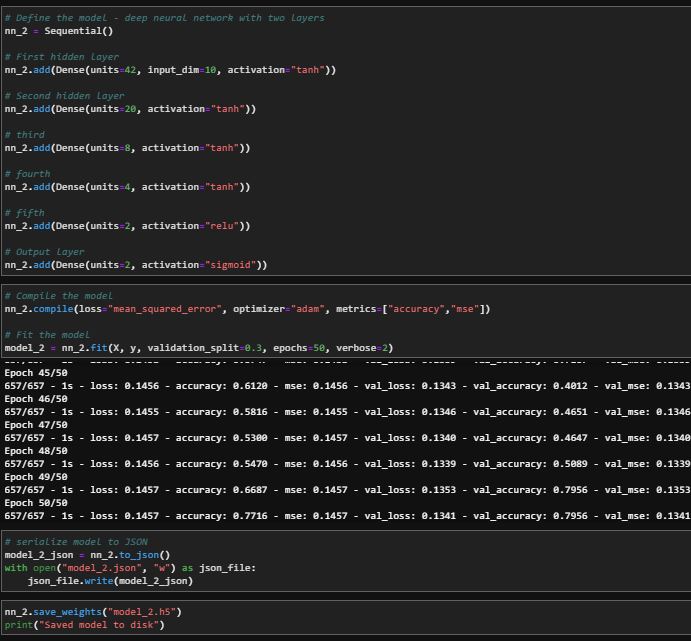
Multiple layer DEEP LEARNING

Evaluation the models
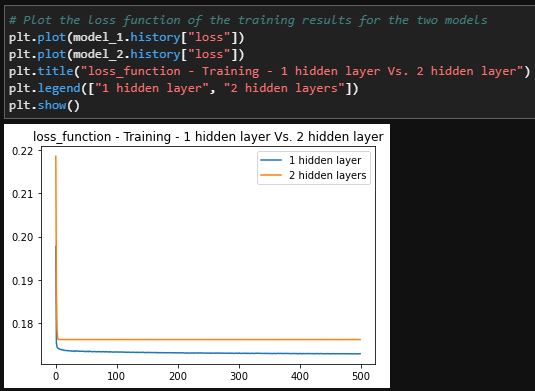
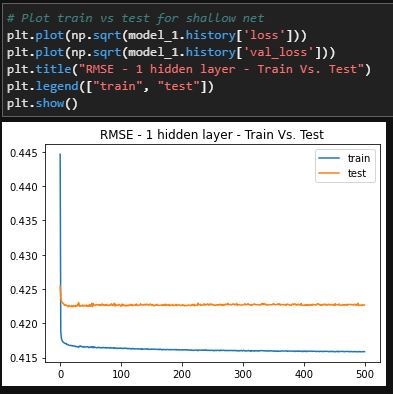
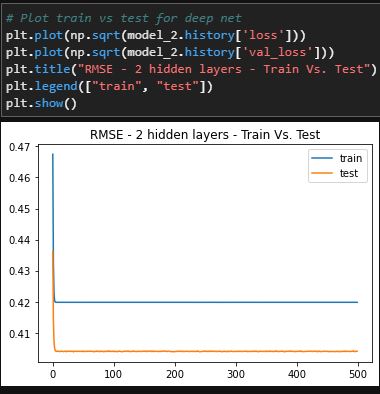
Final Verdict

The deep learning methods were the best methods to solve this problem. Though there were small differences between the single and multiple hidden layer methods, the single layer method performed better. The single hidden layer has a loss metric of 17.3% and an accuracy of 78% for training while testing data shows 17.9% loss and 77% accuracy. Even though the multi hidden layered method had a similar accuracy score for training and testing data, the testing data outperformed the training data which implies that this method is slightly overfit.
If I was using this to solve a similar problem for a potential client, I would use this method because, in theory I was able to increase the accuracy by almost 20% when compared to the original results.
Chat Bots
For each machine learning model I created a chat bot using Amazon Lex and Amazon Lambda. I saved each model to a pickle file. This means that I can send these files to anyone in the world and the model is ready to be deployed; There is no need to train the model or manipulate the data. This solution is truly “plug and play.”
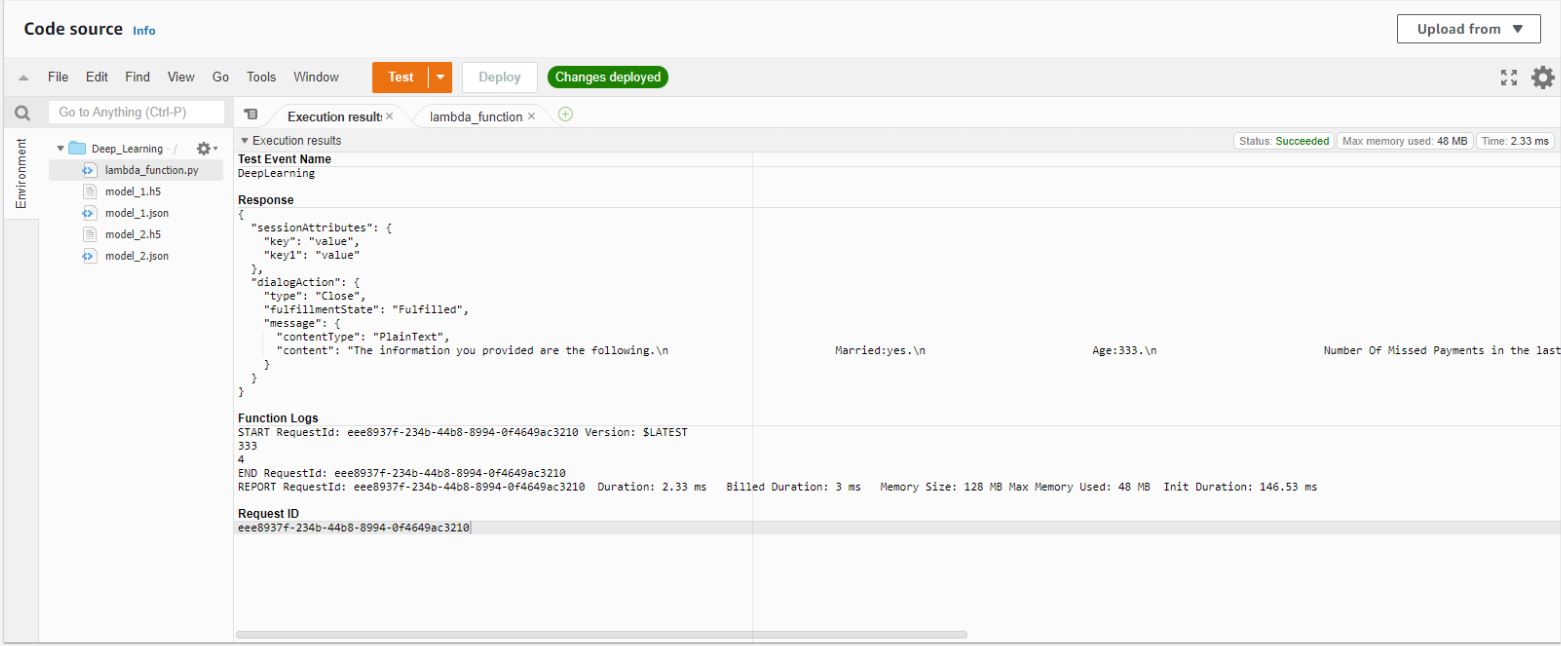
Machine learning AWS Lambda function
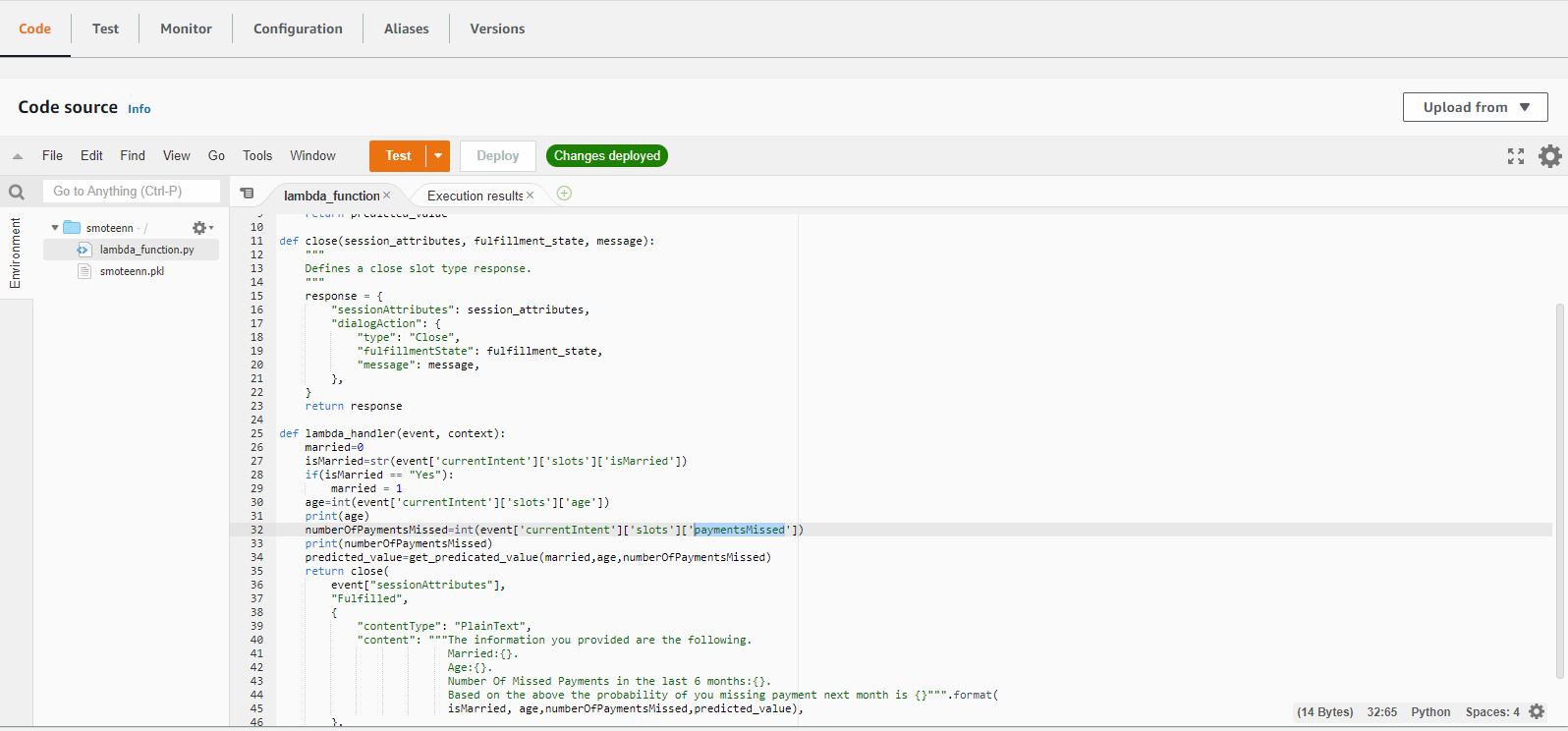
Machine learning bot video
Deep Learning lambda function